 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchSIBench: Benchmarking the Architectural Spatial Intelligence of Vision-Language Models
May 20, 2026Architectural spatial intelligence, the ability to recognize and infer architectural space, is fundamental to tasks such as robot navigation, embodied interaction, and 3D scene understanding and generation. Although extensive research has evaluated the basic spatial skills of Vision-Language Models (VLMs) such as relative orientation, distance comparison, and object counting, these tasks cover only the most elementary levels of spatial cognition and largely overlook higher-level cognition of architectural space, including layout understanding, circulation patterns, and functional zoning. In this work, we present ArchSIBench, a Benchmark for Architectural Spatial Intelligence based on the perspectives from architecture, cognitive science, and psychology. ArchSIBench covers five core dimensions: perception, reasoning, navigation, transformation, and configuration, comprising 17 fine-grained subtasks. Through careful manual annotation by experts with architectural backgrounds, we construct 3,000 question-answer pairs to enable comprehensive evaluation of architectural spatial intelligence. Based on ArchSIBench, we evaluate various VLMs and find that the architectural spatial intelligence of most models shows significant differences from human baselines; additionally, models exhibit substantial variability across capability dimensions. Some state-of-the-art models can approach the level of human evaluators without architectural training. However, a clear gap remains compared to human evaluators with architectural training, particularly in spatial transformation and configuration reasoning. We believe that ArchSIBench will provide important insights and systematic resources for measuring and advancing the architectural spatial intelligence of VLMs. The dataset and code are available at https://huggingface.co/datasets/ArchSIBench/ArchSIBench.
Sketch2MinSurf: Vision-Language Guided Generation of Editable Minimal Surfaces from Hand-Drawn Sketches
May 20, 2026Converting hand-drawn sketches into structured 3D geometries remains challenging due to the difficulty of representing non-Euclidean surfaces and maintaining topological consistency. Existing generative models such as GANs, NeRFs, and diffusion architectures often fail to produce editable manifolds directly usable in downstream design workflows. We present Sketch2MinSurf, a hybrid vision-language and geometric optimization framework that integrates vision-language guidance with minimal-surface theory to generate smooth and editable 3D surfaces from hand-drawn sketches. The core of our approach is a spatial-topological encoding that represents geometry as tuples of node coordinates and real/virtual edge skeletons, enabling stable topological control during generation. We further introduce the Sketch2MinSurf Structural Loss (S2MS-Loss), a reward-modulated objective that jointly constrains geometric reconstruction and topological coherence. On a test set of 100 sketches, Sketch2MinSurf achieves a topological similarity score of 0.844, outperforming existing sketch-to-shape baselines. The generated manifolds are directly editable and free from non-manifold artifacts. A public art installation at a university showcases the method's potential for human-intent-driven 3D form generation. The dataset and code are available at https://anonymous.4open.science/r/Sketch2MinSurf/.
AbFlow : End-to-end Paratope-Centric Antibody Design by Interaction Enhanced Flow Matching
Feb 06, 2026Antigen-antibody binding is a critical process in the immune response. Although recent progress has advanced antibody design, current methods lack a generative framework for end-to-end modeling of full-atom antibody structures and struggle to fully exploit antigen-specific geometric information for optimizing local binding interfaces and global structures. To overcome these limitations, we introduce AbFlow, a flow-matching framework that leverages optimal transport to design full-atom antibodies end-to-end. AbFlow incorporates an extended velocity field network featuring an equivariant Surface Multi-channel Encoder, which uses surface-level antigen interaction data to refine the antibody structure, particularly the CDR-H3 region. Extensive experiments in paratoep-centric antibody design, multi-CDRs and full-atom antibody design, binding affinity optimization, and complex structure prediction show that AbFlow produces superior antigen-antibody complexes, especially at the contact interface, and markedly improves the binding affinity of generated antibodies.
Fused Gromov-Wasserstein Contrastive Learning for Effective Enzyme-Reaction Screening
Dec 09, 2025Enzymes are crucial catalysts that enable a wide range of biochemical reactions. Efficiently identifying specific enzymes from vast protein libraries is essential for advancing biocatalysis. Traditional computational methods for enzyme screening and retrieval are time-consuming and resource-intensive. Recently, deep learning approaches have shown promise. However, these methods focus solely on the interaction between enzymes and reactions, overlooking the inherent hierarchical relationships within each domain. To address these limitations, we introduce FGW-CLIP, a novel contrastive learning framework based on optimizing the fused Gromov-Wasserstein distance. FGW-CLIP incorporates multiple alignments, including inter-domain alignment between reactions and enzymes and intra-domain alignment within enzymes and reactions. By introducing a tailored regularization term, our method minimizes the Gromov-Wasserstein distance between enzyme and reaction spaces, which enhances information integration across these domains. Extensive evaluations demonstrate the superiority of FGW-CLIP in challenging enzyme-reaction tasks. On the widely-used EnzymeMap benchmark, FGW-CLIP achieves state-of-the-art performance in enzyme virtual screening, as measured by BEDROC and EF metrics. Moreover, FGW-CLIP consistently outperforms across all three splits of ReactZyme, the largest enzyme-reaction benchmark, demonstrating robust generalization to novel enzymes and reactions. These results position FGW-CLIP as a promising framework for enzyme discovery in complex biochemical settings, with strong adaptability across diverse screening scenarios.
Learning from Simulated and Unsupervised Images through Adversarial Training
Jul 19, 2017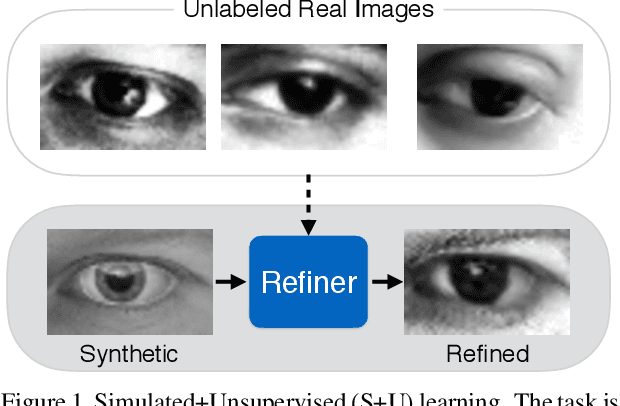

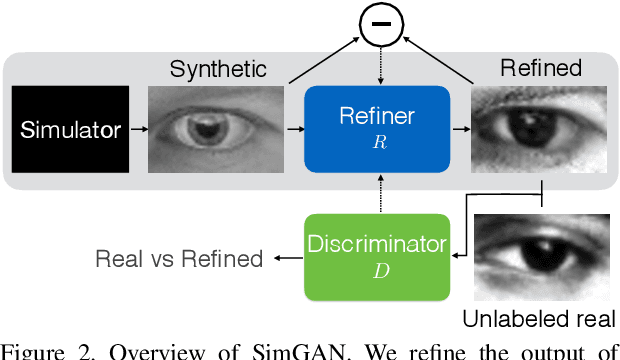
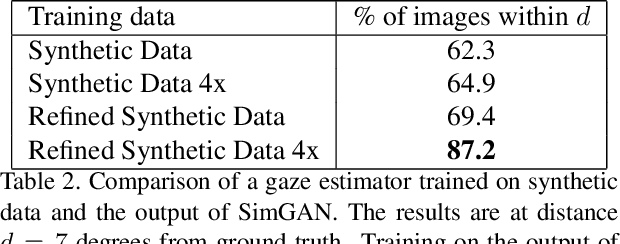
With recent progress in graphics, it has become more tractable to train models on synthetic images, potentially avoiding the need for expensive annotations. However, learning from synthetic images may not achieve the desired performance due to a gap between synthetic and real image distributions. To reduce this gap, we propose Simulated+Unsupervised (S+U) learning, where the task is to learn a model to improve the realism of a simulator's output using unlabeled real data, while preserving the annotation information from the simulator. We develop a method for S+U learning that uses an adversarial network similar to Generative Adversarial Networks (GANs), but with synthetic images as inputs instead of random vectors. We make several key modifications to the standard GAN algorithm to preserve annotations, avoid artifacts, and stabilize training: (i) a 'self-regularization' term, (ii) a local adversarial loss, and (iii) updating the discriminator using a history of refined images. We show that this enables generation of highly realistic images, which we demonstrate both qualitatively and with a user study. We quantitatively evaluate the generated images by training models for gaze estimation and hand pose estimation. We show a significant improvement over using synthetic images, and achieve state-of-the-art results on the MPIIGaze dataset without any labeled real data.